Privacidad en Big Data
En la sociedad del conocimiento actual, la verdadera riqueza de las empresas no estará solo en el desarrollo y desempeño de su core -ya sean productos o servicios-, sino en cómo lo puedan monetizar mediante la explotación de sus datos y el uso de las TI.
- Inteligencia artificial y 'big data', un binomio de éxito para 2018
- Velocidad, seguridad y big data: protagonistas en 'networking'
- GDPR: ¿Estamos seguros de saber lo que hay que hacer?
- El Gobierno adaptará la LOPD a las consignas del nuevo Reglamento Europeo de Protección de Datos
- NoBlue da las claves para adaptarse al GDPR de una manera correcta y sencilla

Si intentamos vaticinar las principales tendencias de las Tecnologías de la Información (TI) que estarán en boca de todos durante los próximos cinco años, tenemos claro que el Big Data y la Inteligencia Artificial estarán a la cabeza. Pero ¿y las siguientes posiciones? La ciberseguridad y la digitalización orientada al cumplimiento de leyes, regulaciones y aspectos sociales y éticos (en estricto tiempo real) prometen pelear duro debido al manejo y la explotación de grandes volúmenes de datos.
La compleja relación que existe entre el Big Data y los requisitos cada vez más inevitables de confidencialidad, privacidad y confianza en los datos, marcan los límites de un nuevo campo multidisciplinar. Un terreno fascinante en el que conviven diariamente trazos de computación, ingeniería, sistemas de la información, economía, ciencias sociales y políticas, y factores éticos y humanos. Un terreno también complejo a la hora de aplicar correctamente las exigidas privacidad y seguridad en los sistemas Big Data que gobiernan todas estas disciplinas, en las que se mueven y cruzan en tiempo real volúmenes ingentes de datos.
La evolución del Big Data había relegado los factores de seguridad y privacidad a un segundo plano, a un “hasta que no sea regulatoriamente inevitable...”. Hasta ahora. Con el Reglamento General de Protección de Datos (GDPR) a la vuelta de la esquina, muchos miedos se han hecho presentes: sin confidencialidad los datos estarán expuestos al alcance de cualquier persona malintencionada, sin privacidad el adversario puede identificar los datos que busca, y, sin el debido gobierno, nuestros datos pueden falsearse fácilmente. Obviamente, sobra explicar que si nuestro negocio son los datos, no protegerlos es cavar nuestra propia tumba.
Con la entrada en vigor el próximo 25 de mayo de 2018 en toda la Unión Europea del GDPR -de carácter mucho más general que las leyes nacionales, como nuestra LOPD- se sentarán unas nuevas bases que, por su carácter general y regulador, evitarán las complejas injerencias nacionales y sentarán claramente las bases de cómo ha de cumplirse la regulación, definiendo importantes sanciones (hasta un 4% de los beneficios de la empresa infractora en ese año).
A la vista de todo esto, la pregunta surge sola: ¿qué es lo que los proveedores de plataformas y soluciones Big Data están investigando e implementando? ¿Cómo añadirán el cumplimiento de la GDPR a las funcionalidades de sus productos?
Acompañamos al dato en su ciclo de vida para dibujar el nuevo camino de privacidad:
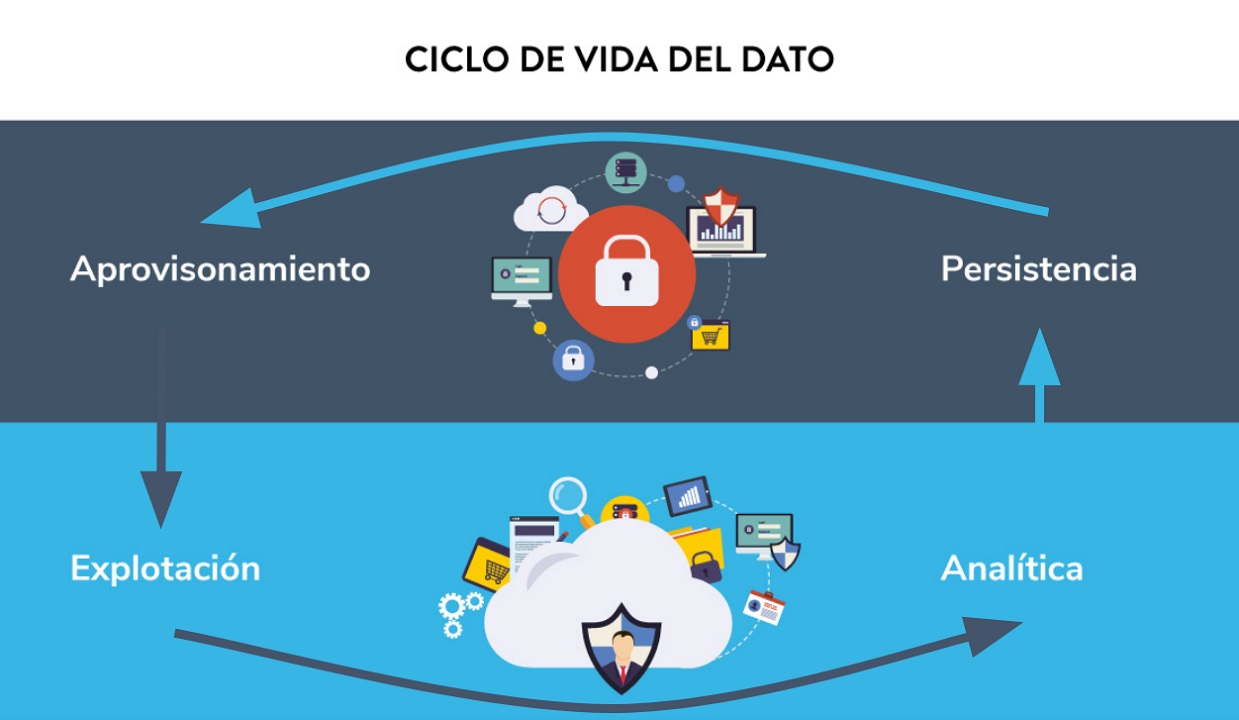
APROVISIONAMIENTO
El aprovisionamiento de datos debe contrastar la fuente de origen e incorporarla al linaje como procedencia fiable: se garantizará que los datos se utilizan para lo que fueron recogidos, además de asegurar que se cumplen las políticas de privacidad. Para ello se debe establecer una red de confianza entre las partes que intercambian los datos a través de comunicaciones cifradas (confidencialidad, privacidad y autenticación). Cada parte se compromete al uso adecuado de los datos e informará del estado de los mismos, garantizando su cumplimiento.
PERSISTENCIA
Los datos recibidos son almacenados en una zona de desembarco, en el formato original autocontenido, que permitirá el acceso único para los fines para los que fueron recogidos. Cualquier transformación realizada sobre los datos quedará trazada siguiendo un modelo de gobierno adecuado que otorgará a estos datos una política de acceso coherente a la política general de seguridad. A partir de este punto, se deberán aplicar diferentes niveles de persistencia en zonas cada vez más seguras: confidencialidad.
Debido a la naturaleza particular de los datos, se necesitan diferentes sistemas de almacenamiento de naturaleza heterogénea (datos estructurados y no estructurados). Por lo tanto, la plataforma Big Data debe contar con una capa superior de acceso a datos capaz de relacionar múltiples sistemas de almacenamiento y de aplicar las políticas de seguridad definidas a todos los niveles. Esto no impedirá que en cada sistema de gestión de bases de datos se puedan definir políticas particulares de acceso a registros concretos.
ANALÍTICA
Los resultados de las consultas y los procesos analíticos sobre los datos no se entregarán directamente al usuario, aunque este tenga acceso, ya que antes han de aplicarse las medidas de sanidad pertinentes. Al cruzar datos de diferentes fuentes, es fácil que la privacidad se vea comprometida, asociando información sensible a identificadores implícitos que por su escasa representación en los datos permitan la identificación de los mismos.
Por lo tanto, los resultados analíticos deben anonimizar adecuadamente, añadiendo, por ejemplo, registros similares que impidan la re-identificación. Este proceso es importante ya que es fundamental que además la estructura de los datos y por lo tanto su utilidad analítica no puedan ser alteradas por el proceso de anonimización.
Tanto para esta fase analítica como para la siguiente de explotación es imprescindible hacer un análisis previo del consentimiento de la parte interesada. Este consentimiento nos permitirá asegurar que los datos son adecuados y pertinentes, y están limitados según los fines para los que serán tratados, según el concepto de minimización de datos que contempla la GDPR.
EXPLOTACIÓN
En la última fase del ciclo de vida del dato, los resultados analíticos deben poder explotarse y consumirse de forma segura. Esto genera la necesidad de implementar sistemas de compartición de datos que aseguren los niveles adecuados de confidencialidad, propiedad y privacidad proporcionando la mínima información necesaria (“Protección del dato por diseño y por defecto” que recoge la GDPR).
Dado el enorme valor de los datos y su fuerte regulación, los datos pertenecientes a una compañía no pueden quedar fuera de la custodia de esta, como resultado de los procesos analíticos. Por lo tanto, las plataformas Big Data tendrán que contar con sistemas capaces de orquestar y distribuir las cargas analíticas entre cada parte, en función de los datos y las capacidades analíticas que posea, para formar cada parte del análisis completo y finalmente entregar a la destinataria (o a un tercero) tan solo los resultados finales, sin generar posibilidad alguna de reconstrucción de toda la fuente de datos como fin de extracción no consentida.
INTELIGENCIA ARTIFICIAL
El conjunto de procesos de gestión que comprenden el almacenamiento en múltiples niveles de persistencia, su acceso seguro, la securización de los resultados de consultas analíticas y la compartición entre distintas partes, constituyen una capa transversal de seguridad y control cuyos procesos son sumamente complejos computacionalmente. En las plataformas Big Data donde el movimiento y la transformación de datos es masiva, esa gestión sería inabarcable por personal humano cualificado. Por esta razón, la gestión de todas estas tareas tendrá necesariamente que recurrir a procesos de inteligencia artificial con capacidades de ciberseguridad y de gobierno del dato.
VERACIDAD Y VALOR
Para finalizar, es inevitable recalcar que el Big Data tiene que realizarse sobre datos fiables. Mucho se ha hablado de las dos últimas Vs del Big Data: Veracidad y Valor, vitales para la aplicación de la seguridad y la calidad.
Muchos estudios recientes se corresponden con análisis que parten de un conocimiento previo (por ejemplo, datos extraídos de una base de datos de publicaciones médicas) que es cruzado con un dato proveniente de resultados obtenidos mediante algoritmos de inteligencia artificial aplicados sobre grandes volúmenes de datos (por ejemplo, estudios de comparaciones de genomas completos en miles de personas). El resultado nos permite descubrir nuevos conocimientos, seguramente impactantes, pero que sin embargo pueden no tener valor al estar basados en datos sesgados o silenciados durante el aprendizaje de la máquina.
Por lo tanto, garantizar la calidad y veracidad del dato y promoverla es determinante. Las superplataformas Big Data que se desarrollen en los próximos años permitirán a las empresas acumular y gestionar todos los datos internos y externos que necesiten, además de gobernarlos, compartirlos y monetizarlos de una manera segura que garantice la continuidad y la sostenibilidad de los negocios.
En la sociedad del conocimiento actual, la verdadera riqueza de las empresas no estará solo en el desarrollo y desempeño de su core -ya sean productos o servicios-, sino en cómo lo puedan monetizar mediante la explotación de sus datos y el uso de las TI. Esto abrirá el camino a nuevas cotas de digitalización y crecimiento económico que marcarán los nuevos modelos de negocio. Ojalá, de manera sostenible.
 |
Raúl De la Fuente LopesLicenciado en Informática, Ingeniero en Sistemas y Master en Neurociencia aplicada al negocio. Actualmente, trabaja como Preventa Big Data en StratioBD. Colaborador Blockchain en Eliumtech. Fundador de la comunidad Neutalk. Anteriormente, ha trabajado como Business Analytics Architect en Altran Tessella. Profesor de Transformación Digital en la plataforma de Bejob Santillana y profesor invitado en la Universidades URJC y UEM. Madrid, España. |
|
|
Carlos Quijano San MartinDoctor en bioinformatica. Master en Big Data y Data Scientist. En la actualidad trabaja como ingeniero de negocio en StratioBD. Sus campos de interés son la ciberseguridad, machine learning y sistemas distribuidos. Madrid, España. |